Proposing a Foundation Model Information-Sharing Regime for the UK
We propose an information-sharing regime between leading AI labs and the UK Office for Artificial Intelligence. This regime could support anticipatory policymaking and reduce risks.
Nikhil Mulani and Jess Whittlestone
This post outlines a concrete proposal for a pilot information-sharing regime, to give the UK government foresight into emerging risks and opportunities from AI.
GovAI research blog posts represent the views of their authors, rather than the views of the organisation.
Summary
The United Kingdom aims to become a global AI superpower, while also safely navigating the risks AI poses. However, there is an important gap in the government’s ability to achieve these goals: it cannot see advances in AI capabilities coming. As a result, it cannot easily prepare for new opportunities and risks.
This week, in recognition of this problem, the UK government secured pledges from three leading AI labs to provide “early access” to their models. However, this pledge has yet to be operationalised. It also is not clear that early access to new AI systems will, on its own, grant the government sufficiently thorough and longrun foresight.
To more systematically address the “foresight gap,” we propose that the UK government create an information-sharing regime between AI labs and the Office for Artificial Intelligence. This post outlines a concrete pilot proposal, based on interviews with think tank researchers, UK government staff working on AI policy issues, and staff at leading AI labs.1
We recommend that the Office for Artificial Intelligence set up a voluntary information-sharing pilot program with frontier AI labs, centered on model capability evaluations and compute usage. Such information-sharing would only be encouraged for a limited subset of new foundation models, which are especially compute-intensive or have especially general capabilities. This information could be shared both before and throughout model training and deployment processes. Shortly before release, in line with the recently announced commitments, labs could also grant the Office direct access to their models.
Subject-matter experts employed by the Office – or seconded from partner organisations – could analyse this information for its implications about current risks and forthcoming developments. Then, these experts could communicate actionable policy recommendations to relevant stakeholders throughout the UK government. For instance, recommendations could inform government efforts to develop technical standards and regulatory frameworks for foundation model development, or help the government to plan for national security incidents related to AI safety failures and misuse.
Foundation Models: Risks and Opportunities
Foundation models are AI systems that can be applied or adapted to perform a wide range of tasks. As is noted in the recent UK whitepaper on AI regulation, the general-purpose capabilities of foundation models could have a transformative impact on society and should be a primary focus of government monitoring and horizon-scanning efforts for AI.
The degree of risk posed by current foundation models is contentious. However, continued progress could produce models that pose considerable risks across political, cyber, biotech, and critical infrastructure domains.2 Some experts believe that increasingly dangerous capabilities could emerge rapidly. At the same time, these models promise to enable significant efficiencies in areas such as healthcare and education.
The Need for a New Information-Sharing Regime
The capabilities of new foundation models are growing more quickly than the government can design and implement AI policy. The natural result of this gap is a hasty and panicked approach to policymaking, as was evident in the wake of the ChatGPT launch.3
AI policymaking will have reduced effectiveness if it continues to be driven reactively after the launches of increasingly powerful AI systems. Policymakers need to be able to foresee potential harms from forthcoming systems, in order to prepare and take proactive policy actions. It is also important for policymakers to understand how development and risk mitigation practices are evolving within labs.
Unfortunately, public information about foundation model development is actually becoming scarcer. Up until recently, AI labs disclosed compute requirements and model design details alongside new large model releases. With the release of GPT-4, OpenAI declined to share compute and model details due to competition and safety concerns. Secrecy around development practices may continue to increase as AI capabilities advance. At the same time, as labs adopt new pre-release risk management practices, the lag between new capabilities being developed and being announced to the world may grow as well.
However, in recognition of these issues, lab leaders have stated a willingness to share sensitive details about their work with policymakers so that the public interest can be protected.4 The UK government should take lab leaders up on their offer and work to build an information-sharing regime.
Proposing a Pilot Information-Sharing Program
We propose a voluntary pilot that centers on two types of information: model capability evaluations, which are helpful for assessing the potential impacts of new models,5 and compute requirements, which provide insight into the trajectory of artificial intelligence development.6 Model capability evaluations and compute requirements would each be voluntarily reported to the Office for Artificial Intelligence by frontier labs both ahead of and during deployment for a limited subset of new foundation models that surpass some level of compute usage or general-purpose capability. Using this information, the Office for Artificial Intelligence can monitor progress in capabilities and communicate suggested policy actions to relevant bodies throughout the government, to reduce risks and ensure the impact of new foundation models is beneficial.
Model capability and compute requirement information could be provided in the form of a training run report, which labs share at a few different milestones: before they begin the training process for new foundation models, periodically throughout the training process, and before and following model deployment.7
Training Run Reports
Training run reports7 could contain the following elements:
Capability evaluations: Knowledge of new foundation model capabilities will allow policymakers to identify likely risks and opportunities that deployment will create and to prepare for these proactively. Industry labs are already generating capability information by using benchmarks to quantify the model’s performance in its intended use cases. Labs are also performing both quantitative and qualitative evaluations which seek to identify harmful tendencies (such as bias or deceptiveness) and unintended dangerous capabilities (such as the ability to support cyberattacks). Details provided to the Office for Artificial Intelligence team could include:
- Descriptions of the model’s intended use cases, as well as performance benchmarks for tasks it is expected to perform.
- A full accounting of the evaluations run on the model at pre-training and pre-deployment stages and their results, including evaluations intended to identify harmful tendencies and high-risk dangerous capabilities (e.g. cyber-offense, self-proliferation, and weapon design).8
- Details about the size and scope of the evaluation effort, including the parties involved and the safeguards in place during evaluations.
Compute requirements: Knowledge of the compute used to train foundation models will provide policymakers with the context necessary to forecast future model capabilities and to monitor how underlying technical factors that influence model research and development, such as compute efficiency, are progressing. Information about compute usage is also helpful for assessing the climate impacts of AI.9 Ultimately, compute trends will allow policymakers to estimate the pace at which they should implement policies to prepare for forthcoming risks and opportunities. Industry labs already possess compute infrastructure information, since they must plan ahead and budget for compute requirements when designing a new foundation model. Details provided to the Office for Artificial Intelligence team could include:
- The amount of compute used (FLOP/OPs) and training time required (e.g. number of GPU hours).
- The quantity and variety (e.g. Nvidia A100) of chips used and a description of the networking of the compute infrastructure.
- The physical location and provider of the compute.
Increasingly complete versions of the training report could be shared across the different stages of the development pipeline: before model training, during the training process, before model deployment, and after model deployment. If possible, in order to give sufficient foresight, it would be desirable for at least one month before training and one month before deployment.
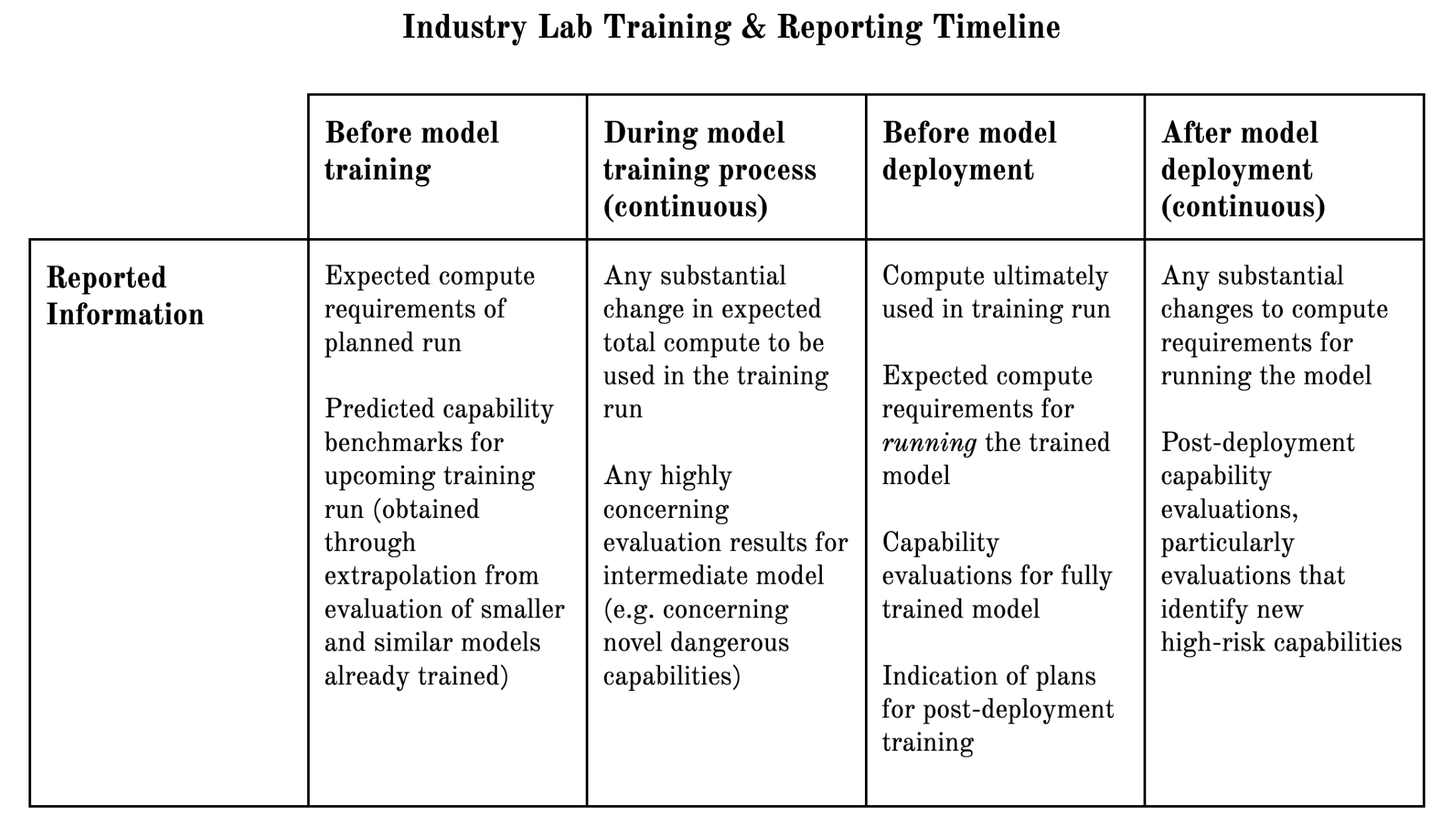
In the pre-deployment stage, as a complement to the training report, companies may also be encouraged to offer early access to their fully trained models. Direct model access is a not a substitute for training reports, as training reports: (a) are likely to contain results from some evaluations that the government does not currently have the capacity or expertise to run, (b) contain some information that one cannot learn simply by using a model, and (c) allow the government to learn certain valuable information before a model is fully trained. However, the government may also be able to learn some additional useful information by interacting directly with the model.
Team Structure and Implementation
This information-sharing program requires the capacity to effectively engage with AI lab staff, perform analysis, and disseminate findings across relevant policy bodies. To handle these tasks, the program could consist of a policy manager and two subject-matter experts. These subject-matter experts could potentially be identified and hired using a secondment program such as the DSIT Expert Exchange or also brought on through existing partnerships with publicly-funded technical research groups such as the CDEI. As an expert organisation working on relevant research, the Centre for the Governance of AI would also be willing to participate in or help facilitate secondment efforts for this program.
We suggest that a natural home for the project would be the Office for Artificial Intelligence. Alternatively, however, the project could be structured as an initiative within the Foundation Models Taskforce or as a more independent body akin to the Cyber Security Information Sharing Partnership within the National Cyber Security Centre.
In any case, there should also be a role with this team’s processes for third-party and academic organisations to participate in a consultation period for its resulting policy recommendations.10 This will help to ensure a diverse and representative set of viewpoints is included in its final guidance to policymakers.
This program should include robust information security measures to reduce the risks of sensitive AI development details leaking and ending up in the hands of other labs (who might gain a competitive advantage) or bad actors (who might find ways to exploit the information). Technical security measures should be in place for ensuring that unredacted training run reports are only accessible to a limited set of high-trust team members within the Office for Artificial Intelligence. Program administrators and lab partners could also collaboratively define an information-sharing protocol and require that the protocol be adhered to whenever new information is disclosed from one party to another.11 This helps ensure all program participants are aligned on how a specific piece of information can be used or whether it can be disseminated to other government stakeholders. Over time, such protocol rules could also be enforced through the technical architecture of a data portal and APIs by using structured transparency techniques.
Policy Outcomes from Information-Sharing
A voluntary information-sharing regime between the UK government and AI labs would build frontier AI expertise within the Office for Artificial Intelligence and create working relationships with UK-based industry labs. Key government recipients of policy recommendations could include:
- Expert bodies (including AI Standards Hub, CDEI, and BSI) that can use recommendations as inputs for developing technical standards, for instance compute and capability benchmarks for legal categorization of foundation models.
- Regulators (including agency members of the DRCF and the EHRC) that can use recommendations as input for creating guidelines for model transparency and developing industry best-practice guidelines to prevent large-scale risks.
- Security and scientific advisory bodies (including NSC, CST, and SAGE) that can use recommendations as inputs for national security planning to reduce and prepare for risks from AI misuse and AI safety failures.
Over time, we imagine that the information-sharing program could scale to further information types and policy recommendation areas. Additionally, it could begin interfacing with a wider set of international AI labs and coordinating with relevant foreign government and multilateral offices focused on AI monitoring and evaluation (such as the NIST AI Measurement and Evaluation program in the United States or the Security and Technology Programme at the United Nations). Eventually, the program’s findings could help to inform an overall policy regime that steers AI development in a direction that is beneficial for the United Kingdom’s future.
Challenges and Concerns
Importantly, implementing an information-sharing program would not be without risks or costs. One challenge, as noted above, would be to ensure that sensitive information reported by labs does not leak to competitors or bad actors. We believe that a small government unit with strong information-security requirements would be unlikely to produce such leaks. Nonetheless, in order to secure lab buy-in, it would be important for this risk to be taken quite seriously.
Second, it would be important to ensure that the program does not disincentivize labs from performing evaluations that might reveal risks. To reduce the chance of any disincentive effect, it may be important to provide specific assurances about how information can be used. Assurances concerning liability protection could also conceivably be worthwhile.12
The authors of this piece can be contacted at nikhil.mulani.wg20@wharton.upenn.edu and jess@longtermresilience.org.
Footnotes
1 Research for this proposal included three rounds of interviews with stakeholders for a pilot information-sharing program. The first set of interviews focused on AI policy researchers who have published work on related issues and questions, including researchers at the Centre for the Governance of AI and the Center for Security and Emerging Technology. The second set of interviews focused on UK government professionals at departments including the Office for Artificial Intelligence; the Government Office for Science; the Foreign, Commonwealth and Development Office; the Competition and Markets Authority; and the Department of Digital Culture, Media and Sport. The third set of interviews focused on staff at frontier AI labs.
2 Concerns about getting ahead of frontier AI misuse and accident risks are shared by leaders and UK allies across the world. Jen Easterly, Director of the United States’ Cybersecurity and Infrastructure Security Agency, voiced her worries about how current AI capabilities can be applied in the context of cyber warfare, genetic engineering, and bio-weaponry. In particular, Easterly called out the lack of adequate governance tools to monitor and respond to new AI capabilities as “the biggest issue we will have to deal with this century.”
3 See reactions by privacy regulators and education officials, for instance.
4 In a recent interview, OpenAI CEO Sam Altman said that “the thing that [he] would like to see happen immediately” is the government having “much more insight into what companies like ours are doing, companies that are training above a certain level of capability at a minimum.”
5 For more on the increasing importance of model evaluations, see (e.g.) Stanford, 2022; ARC, 2023; and OpenAI, 2023.
6 The UK government whitepaper on AI regulation notes “one way of monitoring the potential impact of LLMs could be by monitoring the amount of compute used to train them, which is much easier to assess and govern than other inputs such as data, or talent. This could involve statutory reporting requirements for models over a certain size.”
7 Training run reports would share some similarities with “model cards,” a post-release reporting framework developed by Mitchell et al.
8 For a discussion of several relevant dangerous capabilities, see Shevlane et al, 2023.
9 To better understand the climate impacts of models, it may also be useful to directly report the energy requirements for training and running the models (e.g. in Watts-hours).
10 Including organisations such as the Alan Turing Institute, Oxford Internet Institute, or the Centre for the Governance of AI.
11 This protocol could look similar to the United States’ Cybersecurity and Infrastructure Security Agency’s Traffic Light Protocol.
12 Additionally, mandatory or redundant information-sharing may reduce the amount and quality of information shared by program participants. This information-sharing proposal only suggests voluntary reporting by labs, to a single body, in part to reduce the reporting burden. As the program grows, it could be important for officials to ensure that labs do not face identical information-sharing requests from multiple sources.